Hadoopインストール(2)
昨日に引き続きHadoop導入.で,その個人的備忘録.
そんなこんなでやっとこさHadoop本体の設定.
とりあえず参考させて頂いたのは,次のサイト.
・http://hadoop.apache.org/common/docs/current/quickstart.html
・http://hadoop.apache.org/common/docs/current/cluster_setup.html
・http://metasearch.sourceforge.jp/wiki/index.php?Hadoop
で,とりあえず,/usr/local/hadoop配下にHadoop Common(旧Hadoop Core)を
展開したので,/usr/local/hadoopを,以下$HADOOP_HOMEと表記する.
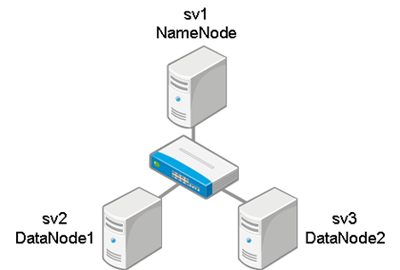
ちなみに,導入した構成は次の通り(再掲).
$HADOOP_HOME/conf/hadoop-env.sh を設定.
変更箇所の説明が面倒なので,diffそのままw
***************
*** 8,10 ****
# The java implementation to use. Required.
! # export JAVA_HOME=/usr/lib/j2sdk1.5-sun
--- 8,10 ----
# The java implementation to use. Required.
! export JAVA_HOME=/usr/local
***************
*** 17,19 ****
# Extra Java runtime options. Empty by default.
! # export HADOOP_OPTS=-server
--- 17,19 ----
# Extra Java runtime options. Empty by default.
! export HADOOP_OPTS=-server
***************
*** 47,49 ****
# The directory where pid files are stored. /tmp by default.
! # export HADOOP_PID_DIR=/var/hadoop/pids
--- 47,49 ----
# The directory where pid files are stored. /tmp by default.
! export HADOOP_PID_DIR=/usr/local/hadoop
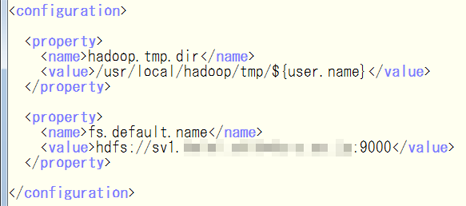
次に,$HADOOP_HOME/conf/core-site.xml
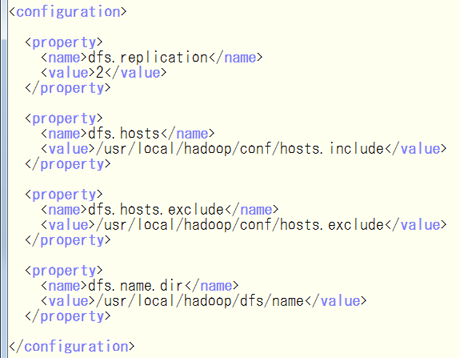
次に,$HADOOP_HOME/conf/hdfs-site.xml
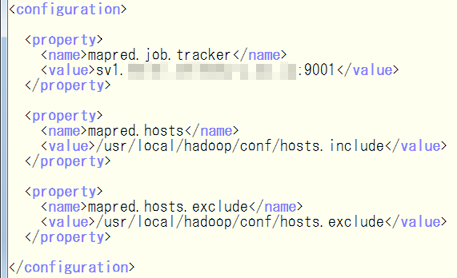
次に,$HADOOP_HOME/conf/mapred-site.xml
あとは,$HADOOP_HOME/conf/masters
sv1.example.com
とりあえず,SecondaryNameNodeは作らない方向で(実験なので).
それと,$HADOOP_HOME/conf/slaves.これは,DataNodeを記述.
sv2.example.com
sv3.example.com
あと,$HADOOP_HOME/conf/hosts.include
とりあえず,全部記述.
sv1.example.com
sv2.example.com
sv3.example.com
$HADOOP_HOME/conf/hosts.excludeは,touchで空ファイル作っておく.
$ touch hosts.exclude
これを作ってなくて,NameNodeが立ち上がらず難儀したw
で,まず,NameNode初期化.
hadoop@sv1> ./bin/hadoop namenode -format
で,sv1(NameNode)上で,$HADOOP_HOME/bin/start-all.shを実行.
問題なければ,sv1〜sv3で,それぞれ次のプロセスが立ち上がる.
hadoop@sv1> jps
15657 JobTracker
15323 SecondaryNameNode
15039 NameNode
hadoop@sv2> jps
96988 DataNode
97320 TaskTracker
hadoop@sv3> jps
45846 DataNode
46177 TaskTracker
試しに,ローカルのファイルをHDFSへコピーしてみる.
hadoop@sv1> hadoop dfs -ls
ls: Cannot access .: No such file or directory.
hadoop@sv1> hadoop dfs -copyFromLocal CHANGES.txt CHANGES.txt
hadoop@sv1> hadoop dfs -ls
Found 1 items
-rw-r--r-- 2 hadoop supergroup 348624 2010-08-14 23:24 /user/hadoop/CHANGES.txt
とまあ,こんな感じ.
次に,http://wiki.apache.org/hadoop/SortにあったSort Benchmarkを試してみた.
hadoop@sv1> ./bin/hadoop jar hadoop-0.20.2-examples.jar randomwriter rand % ./bin/hadoop jar hadoop-0.20.2-examples.jar sort rand rand-sort
Running 20 maps.
Job started: Sat Aug 14 23:34:02 JST 2010
10/08/14 23:34:02 INFO mapred.JobClient: Running job: job_201008142324_0001
10/08/14 23:34:03 INFO mapred.JobClient: map 0% reduce 0%
10/08/14 23:37:15 INFO mapred.JobClient: map 5% reduce 0%
10/08/14 23:37:39 INFO mapred.JobClient: map 10% reduce 0%
10/08/14 23:37:48 INFO mapred.JobClient: map 15% reduce 0%
10/08/14 23:37:51 INFO mapred.JobClient: map 20% reduce 0%
10/08/14 23:40:36 INFO mapred.JobClient: map 25% reduce 0%
10/08/14 23:40:57 INFO mapred.JobClient: map 30% reduce 0%
10/08/14 23:41:36 INFO mapred.JobClient: map 40% reduce 0%
10/08/14 23:44:10 INFO mapred.JobClient: map 45% reduce 0%
10/08/14 23:44:34 INFO mapred.JobClient: map 50% reduce 0%
10/08/14 23:46:03 INFO mapred.JobClient: map 60% reduce 0%
10/08/14 23:48:10 INFO mapred.JobClient: map 65% reduce 0%
10/08/14 23:48:40 INFO mapred.JobClient: map 70% reduce 0%
10/08/14 23:50:52 INFO mapred.JobClient: map 75% reduce 0%
10/08/14 23:51:01 INFO mapred.JobClient: map 80% reduce 0%
10/08/14 23:52:31 INFO mapred.JobClient: map 85% reduce 0%
10/08/14 23:52:52 INFO mapred.JobClient: map 90% reduce 0%
10/08/14 23:55:32 INFO mapred.JobClient: map 95% reduce 0%
10/08/14 23:55:38 INFO mapred.JobClient: map 100% reduce 0%
10/08/14 23:55:40 INFO mapred.JobClient: Job complete: job_201008142324_0001
10/08/14 23:55:40 INFO mapred.JobClient: Counters: 8
10/08/14 23:55:40 INFO mapred.JobClient: Job Counters
10/08/14 23:55:40 INFO mapred.JobClient: Launched map tasks=22
10/08/14 23:55:40 INFO mapred.JobClient: org.apache.hadoop.examples.RandomWriter$Counters
10/08/14 23:55:40 INFO mapred.JobClient: BYTES_WRITTEN=21474967868
10/08/14 23:55:40 INFO mapred.JobClient: RECORDS_WRITTEN=2044752
10/08/14 23:55:40 INFO mapred.JobClient: FileSystemCounters
10/08/14 23:55:40 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=21545717680
10/08/14 23:55:40 INFO mapred.JobClient: Map-Reduce Framework
10/08/14 23:55:40 INFO mapred.JobClient: Map input records=20
10/08/14 23:55:40 INFO mapred.JobClient: Spilled Records=0
10/08/14 23:55:40 INFO mapred.JobClient: Map input bytes=0
10/08/14 23:55:40 INFO mapred.JobClient: Map output records=2044752
Job ended: Sat Aug 14 23:55:40 JST 2010
The job took 1298 seconds.
速いかどうかは別にして,とりあえず動いたってことでw
いずれにせよ,チューニングの前に,もう少しシステム構造を
理解しないといけないなぁ・・・
そんなこんなでやっとこさHadoop本体の設定.
とりあえず参考させて頂いたのは,次のサイト.
・http://hadoop.apache.org/common/docs/current/quickstart.html
・http://hadoop.apache.org/common/docs/current/cluster_setup.html
・http://metasearch.sourceforge.jp/wiki/index.php?Hadoop
で,とりあえず,/usr/local/hadoop配下にHadoop Common(旧Hadoop Core)を
展開したので,/usr/local/hadoopを,以下$HADOOP_HOMEと表記する.
ちなみに,導入した構成は次の通り(再掲).
$HADOOP_HOME/conf/hadoop-env.sh を設定.
変更箇所の説明が面倒なので,diffそのままw
***************
*** 8,10 ****
# The java implementation to use. Required.
! # export JAVA_HOME=/usr/lib/j2sdk1.5-sun
--- 8,10 ----
# The java implementation to use. Required.
! export JAVA_HOME=/usr/local
***************
*** 17,19 ****
# Extra Java runtime options. Empty by default.
! # export HADOOP_OPTS=-server
--- 17,19 ----
# Extra Java runtime options. Empty by default.
! export HADOOP_OPTS=-server
***************
*** 47,49 ****
# The directory where pid files are stored. /tmp by default.
! # export HADOOP_PID_DIR=/var/hadoop/pids
--- 47,49 ----
# The directory where pid files are stored. /tmp by default.
! export HADOOP_PID_DIR=/usr/local/hadoop
次に,$HADOOP_HOME/conf/core-site.xml
次に,$HADOOP_HOME/conf/hdfs-site.xml
次に,$HADOOP_HOME/conf/mapred-site.xml
あとは,$HADOOP_HOME/conf/masters
sv1.example.com
とりあえず,SecondaryNameNodeは作らない方向で(実験なので).
それと,$HADOOP_HOME/conf/slaves.これは,DataNodeを記述.
sv2.example.com
sv3.example.com
あと,$HADOOP_HOME/conf/hosts.include
とりあえず,全部記述.
sv1.example.com
sv2.example.com
sv3.example.com
$HADOOP_HOME/conf/hosts.excludeは,touchで空ファイル作っておく.
$ touch hosts.exclude
これを作ってなくて,NameNodeが立ち上がらず難儀したw
で,まず,NameNode初期化.
hadoop@sv1> ./bin/hadoop namenode -format
で,sv1(NameNode)上で,$HADOOP_HOME/bin/start-all.shを実行.
問題なければ,sv1〜sv3で,それぞれ次のプロセスが立ち上がる.
hadoop@sv1> jps
15657 JobTracker
15323 SecondaryNameNode
15039 NameNode
hadoop@sv2> jps
96988 DataNode
97320 TaskTracker
hadoop@sv3> jps
45846 DataNode
46177 TaskTracker
試しに,ローカルのファイルをHDFSへコピーしてみる.
hadoop@sv1> hadoop dfs -ls
ls: Cannot access .: No such file or directory.
hadoop@sv1> hadoop dfs -copyFromLocal CHANGES.txt CHANGES.txt
hadoop@sv1> hadoop dfs -ls
Found 1 items
-rw-r--r-- 2 hadoop supergroup 348624 2010-08-14 23:24 /user/hadoop/CHANGES.txt
とまあ,こんな感じ.
次に,http://wiki.apache.org/hadoop/SortにあったSort Benchmarkを試してみた.
hadoop@sv1> ./bin/hadoop jar hadoop-0.20.2-examples.jar randomwriter rand % ./bin/hadoop jar hadoop-0.20.2-examples.jar sort rand rand-sort
Running 20 maps.
Job started: Sat Aug 14 23:34:02 JST 2010
10/08/14 23:34:02 INFO mapred.JobClient: Running job: job_201008142324_0001
10/08/14 23:34:03 INFO mapred.JobClient: map 0% reduce 0%
10/08/14 23:37:15 INFO mapred.JobClient: map 5% reduce 0%
10/08/14 23:37:39 INFO mapred.JobClient: map 10% reduce 0%
10/08/14 23:37:48 INFO mapred.JobClient: map 15% reduce 0%
10/08/14 23:37:51 INFO mapred.JobClient: map 20% reduce 0%
10/08/14 23:40:36 INFO mapred.JobClient: map 25% reduce 0%
10/08/14 23:40:57 INFO mapred.JobClient: map 30% reduce 0%
10/08/14 23:41:36 INFO mapred.JobClient: map 40% reduce 0%
10/08/14 23:44:10 INFO mapred.JobClient: map 45% reduce 0%
10/08/14 23:44:34 INFO mapred.JobClient: map 50% reduce 0%
10/08/14 23:46:03 INFO mapred.JobClient: map 60% reduce 0%
10/08/14 23:48:10 INFO mapred.JobClient: map 65% reduce 0%
10/08/14 23:48:40 INFO mapred.JobClient: map 70% reduce 0%
10/08/14 23:50:52 INFO mapred.JobClient: map 75% reduce 0%
10/08/14 23:51:01 INFO mapred.JobClient: map 80% reduce 0%
10/08/14 23:52:31 INFO mapred.JobClient: map 85% reduce 0%
10/08/14 23:52:52 INFO mapred.JobClient: map 90% reduce 0%
10/08/14 23:55:32 INFO mapred.JobClient: map 95% reduce 0%
10/08/14 23:55:38 INFO mapred.JobClient: map 100% reduce 0%
10/08/14 23:55:40 INFO mapred.JobClient: Job complete: job_201008142324_0001
10/08/14 23:55:40 INFO mapred.JobClient: Counters: 8
10/08/14 23:55:40 INFO mapred.JobClient: Job Counters
10/08/14 23:55:40 INFO mapred.JobClient: Launched map tasks=22
10/08/14 23:55:40 INFO mapred.JobClient: org.apache.hadoop.examples.RandomWriter$Counters
10/08/14 23:55:40 INFO mapred.JobClient: BYTES_WRITTEN=21474967868
10/08/14 23:55:40 INFO mapred.JobClient: RECORDS_WRITTEN=2044752
10/08/14 23:55:40 INFO mapred.JobClient: FileSystemCounters
10/08/14 23:55:40 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=21545717680
10/08/14 23:55:40 INFO mapred.JobClient: Map-Reduce Framework
10/08/14 23:55:40 INFO mapred.JobClient: Map input records=20
10/08/14 23:55:40 INFO mapred.JobClient: Spilled Records=0
10/08/14 23:55:40 INFO mapred.JobClient: Map input bytes=0
10/08/14 23:55:40 INFO mapred.JobClient: Map output records=2044752
Job ended: Sat Aug 14 23:55:40 JST 2010
The job took 1298 seconds.
速いかどうかは別にして,とりあえず動いたってことでw
いずれにせよ,チューニングの前に,もう少しシステム構造を
理解しないといけないなぁ・・・