Hadoop-0.21.0 インストール(1)
以前のインストール(その1),(その2)を踏まえ,Hadoopを再インストール.
利用可能な機材が増えたこともあるのだが.
ということで,導入する構成は次の通り.
sv1はNameNode,sv2〜sv4の3台をDataNodeとして稼働させる.
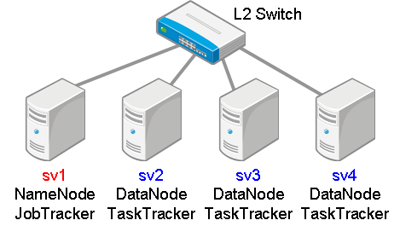
インストール対象OSは,FreeBSD 8.1-STABLE/amd64.
Hadoop以前の下準備として,Java実行環境の導入,hadoopアカウント作成と
sshでのリモートアクセス環境を整備.
今回使用したJavaバージョンは次の通り.
# java -version
java version "1.6.0_07"
Diablo Java(TM) SE Runtime Environment (build 1.6.0_07-b02)
Diablo Java HotSpot(TM) 64-Bit Server VM (build 10.0-b23, mixed mode)
FreeBSDへのDiablo Caffe JDK 1.6インストールは,こちらを参照されたし.
なお,Java実行環境は,当然ながらこれはsv1〜sv4すべてに導入する.
# Hadoop自体がJava上で動作するため.
次に,sv1〜sv4すべてにhadoopアカウントと,同アカウントでの
sshリモートアクセス環境を整備.
とりあえず,/etc/group,/etc/master.passwdに,それぞれエントリhadoopを作成.
GID,UIDとも90としたが特に意味はない.
--- part of /etc/group ---
hadoop:*:90:
--- part of /etc/master.passwd ---
hadoop:*:90:90::0:0:Hadoop Owner:/home/hadoop:/bin/csh
次に,hadoopアカウントでsshキーペアを作成.
sv1上(じゃなくてもいいけど)にて,次のコマンドを投入.
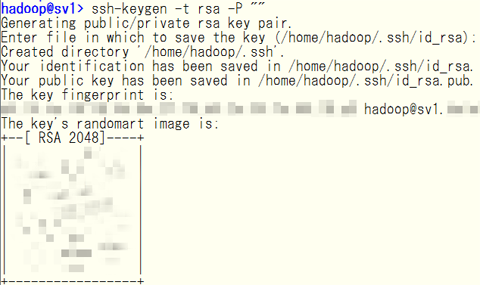
作成されるのは,2048ビット長のRSA公開鍵/秘密鍵のペア.
ちなみに,あえてパスフレーズ無しで生成しています.実験環境なので.
パスフレーズ付きの秘密鍵を使って,パスフレーズをキャッシュさせるには,
ssh-agentを使えばよいようだ.
で,~hadoop/.ssh/配下に,それぞれ次の鍵が生成される.
RSA公開鍵:id_rsa.pub
RSA秘密鍵:id_rsa
パスフレーズなしでリモートアクセスできる必要があるのは,
NameNodeからDataNodeへのログイン(と実行)のみ.
これは,NameNodeからDataNode,JobTrackerからTaskTrackerへの
制御ができればいいため.
つまり,今回の構成では,sv1からsv2〜sv4方向へのログインできればよい.
# 逆方向は不要.
このため,sv1上で作成された,~hadoop/.ssh/id_rsa.pub を,sv2〜sv4の
~hadoop/.ssh/authorized_keysとして追加する.
何らかの方法でsv1の~hadoop/.ssh/id_rsa.pubをsv2〜sv4へコピーし,
cat ~hadoop/.ssh/id_rsa.pub >> ~hadoop/.ssh/authorized_keys
ってな感じ.
ちなみに上記設定後,sv1からhadoopアカウントを用いて,手動でsv2〜sv4へ
ログインしておく.これは,sv2〜sv4のfinger printを,sv1の
~hadoop/.ssh/known_hosts に追加しておくため.
あとは,bashをインストール.これも,sv1〜sv4全部.
Hadoopの起動用/停止用スクリプトは,bashを前提に書かれているため.
ここは手っ取り早くportsでbashを導入.
# cd /usr/ports/shells/bash
# make build ; make install
ここまでで,とりあえず前準備完了w
利用可能な機材が増えたこともあるのだが.
ということで,導入する構成は次の通り.
sv1はNameNode,sv2〜sv4の3台をDataNodeとして稼働させる.
インストール対象OSは,FreeBSD 8.1-STABLE/amd64.
Hadoop以前の下準備として,Java実行環境の導入,hadoopアカウント作成と
sshでのリモートアクセス環境を整備.
今回使用したJavaバージョンは次の通り.
# java -version
java version "1.6.0_07"
Diablo Java(TM) SE Runtime Environment (build 1.6.0_07-b02)
Diablo Java HotSpot(TM) 64-Bit Server VM (build 10.0-b23, mixed mode)
FreeBSDへのDiablo Caffe JDK 1.6インストールは,こちらを参照されたし.
なお,Java実行環境は,当然ながらこれはsv1〜sv4すべてに導入する.
# Hadoop自体がJava上で動作するため.
次に,sv1〜sv4すべてにhadoopアカウントと,同アカウントでの
sshリモートアクセス環境を整備.
とりあえず,/etc/group,/etc/master.passwdに,それぞれエントリhadoopを作成.
GID,UIDとも90としたが特に意味はない.
--- part of /etc/group ---
hadoop:*:90:
--- part of /etc/master.passwd ---
hadoop:*:90:90::0:0:Hadoop Owner:/home/hadoop:/bin/csh
次に,hadoopアカウントでsshキーペアを作成.
sv1上(じゃなくてもいいけど)にて,次のコマンドを投入.
作成されるのは,2048ビット長のRSA公開鍵/秘密鍵のペア.
ちなみに,あえてパスフレーズ無しで生成しています.実験環境なので.
パスフレーズ付きの秘密鍵を使って,パスフレーズをキャッシュさせるには,
ssh-agentを使えばよいようだ.
で,~hadoop/.ssh/配下に,それぞれ次の鍵が生成される.
RSA公開鍵:id_rsa.pub
RSA秘密鍵:id_rsa
パスフレーズなしでリモートアクセスできる必要があるのは,
NameNodeからDataNodeへのログイン(と実行)のみ.
これは,NameNodeからDataNode,JobTrackerからTaskTrackerへの
制御ができればいいため.
つまり,今回の構成では,sv1からsv2〜sv4方向へのログインできればよい.
# 逆方向は不要.
このため,sv1上で作成された,~hadoop/.ssh/id_rsa.pub を,sv2〜sv4の
~hadoop/.ssh/authorized_keysとして追加する.
何らかの方法でsv1の~hadoop/.ssh/id_rsa.pubをsv2〜sv4へコピーし,
cat ~hadoop/.ssh/id_rsa.pub >> ~hadoop/.ssh/authorized_keys
ってな感じ.
ちなみに上記設定後,sv1からhadoopアカウントを用いて,手動でsv2〜sv4へ
ログインしておく.これは,sv2〜sv4のfinger printを,sv1の
~hadoop/.ssh/known_hosts に追加しておくため.
あとは,bashをインストール.これも,sv1〜sv4全部.
Hadoopの起動用/停止用スクリプトは,bashを前提に書かれているため.
ここは手っ取り早くportsでbashを導入.
# cd /usr/ports/shells/bash
# make build ; make install
ここまでで,とりあえず前準備完了w