Hadoop-0.21.0 インストール(2)
引き続き,Hadoop-0.21.0の導入.ここからは基本的に前回と変わらない.
hadoop-0.21.0.tar.gzを取得してきて,/usr/local配下で展開.
すると,/usr/local/hadoop-0.21.0/ が生成される.で,
# ln -s /usr/local/hadoop-0.21.0 /usr/local/hadoop
とでもしておく.
以後,Hadoopを展開したディレクトリを,$HADOOP_HOMEと表記する.
まず,$HADOOP_HOME/conf/hadoop-env.shを設定.
前回同様,面倒なので,diffそのまま掲載w
***************
*** 8,10 ****
# The java implementation to use. Required.
! # export JAVA_HOME=/usr/lib/j2sdk1.6-sun
--- 8,10 ----
# The java implementation to use. Required.
! export JAVA_HOME=/usr/local
***************
*** 17,19 ****
# Extra Java runtime options. Empty by default.
! # export HADOOP_OPTS=-server
--- 17,19 ----
# Extra Java runtime options. Empty by default.
! export HADOOP_OPTS=-server
***************
*** 47,49 ****
# The directory where pid files are stored. /tmp by default.
! # export HADOOP_PID_DIR=/var/hadoop/pids
--- 47,49 ----
# The directory where pid files are stored. /tmp by default.
! export HADOOP_PID_DIR=/usr/local/hadoop
次に,$HADOOP_HOME/conf/core-site.xmlを編集.
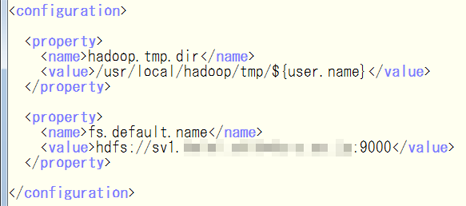
次に,$HADOOP_HOME/conf/hdfs-site.xmlを編集.
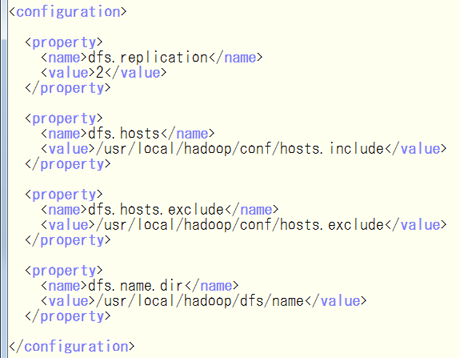
次に,$HADOOP_HOME/conf/mapred-site.xmlを編集.
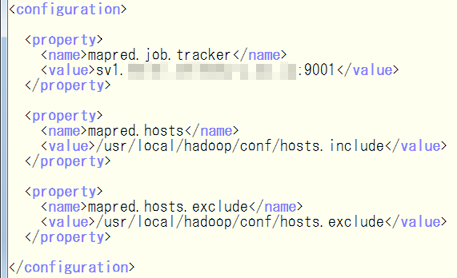
ここまでの設定は,全ノード(すなわちsv1〜sv4)に実行する.
設定内容は,まったく同じで差し支えない.
で,ここからは,NameNode(sv1)のみに設定.
・$HADOOP_HOME/conf/masters設定
sv1.example.com
ってな感じで,NameNodeとなるホスト名を記述.
とりあえず,SecondaryNameNodeは作らない方向で(実験なので).
・$HADOOP_HOME/conf/slaves設定
sv2.example.com
sv3.example.com
sv4.example.com
ってな感じで,DataNodeとなるホスト名を列挙.
あと,$HADOOP_HOME/conf/hosts.include
とりあえず,全部記述.
sv1.example.com
sv2.example.com
sv3.example.com
sv4.example.com
$HADOOP_HOME/conf/hosts.excludeは,touchで空ファイル作っておく.
$ touch hosts.excludeって感じで.
これを作ってなくて,NameNodeが立ち上がらず難儀したw
これで一応設定完了.いよいよ立ち上げ.
まず,NameNode初期化.
hadoop@sv1> ./bin/hadoop namenode -format
で,sv1(NameNode)上で,$HADOOP_HOME/bin/start-all.shを実行.
問題なければ,sv1〜sv4で,それぞれ次のプロセスが立ち上がる.
hadoop@sv1> jps
5478 JobTracker
5025 SecondaryNameNode
4219 NameNode
hadoop@sv2> jps
5933 DataNode
6272 TaskTracker
※sv3,sv4も同様にDataNode,TaskTrackerが立ち上がる.
ま,とりあえずプロセスは起動しましたよ,と.
ちなみにHadoopの停止は,sv1(NameNode)で
$HADOOP_HOME/bin/stop-all.shを実行.
DataNode,TaskTrackerも含め,すべて停止する.
これでとりあえず実行環境まで構築終了.
hadoop-0.21.0.tar.gzを取得してきて,/usr/local配下で展開.
すると,/usr/local/hadoop-0.21.0/ が生成される.で,
# ln -s /usr/local/hadoop-0.21.0 /usr/local/hadoop
とでもしておく.
以後,Hadoopを展開したディレクトリを,$HADOOP_HOMEと表記する.
まず,$HADOOP_HOME/conf/hadoop-env.shを設定.
前回同様,面倒なので,diffそのまま掲載w
***************
*** 8,10 ****
# The java implementation to use. Required.
! # export JAVA_HOME=/usr/lib/j2sdk1.6-sun
--- 8,10 ----
# The java implementation to use. Required.
! export JAVA_HOME=/usr/local
***************
*** 17,19 ****
# Extra Java runtime options. Empty by default.
! # export HADOOP_OPTS=-server
--- 17,19 ----
# Extra Java runtime options. Empty by default.
! export HADOOP_OPTS=-server
***************
*** 47,49 ****
# The directory where pid files are stored. /tmp by default.
! # export HADOOP_PID_DIR=/var/hadoop/pids
--- 47,49 ----
# The directory where pid files are stored. /tmp by default.
! export HADOOP_PID_DIR=/usr/local/hadoop
次に,$HADOOP_HOME/conf/core-site.xmlを編集.
次に,$HADOOP_HOME/conf/hdfs-site.xmlを編集.
次に,$HADOOP_HOME/conf/mapred-site.xmlを編集.
ここまでの設定は,全ノード(すなわちsv1〜sv4)に実行する.
設定内容は,まったく同じで差し支えない.
で,ここからは,NameNode(sv1)のみに設定.
・$HADOOP_HOME/conf/masters設定
sv1.example.com
ってな感じで,NameNodeとなるホスト名を記述.
とりあえず,SecondaryNameNodeは作らない方向で(実験なので).
・$HADOOP_HOME/conf/slaves設定
sv2.example.com
sv3.example.com
sv4.example.com
ってな感じで,DataNodeとなるホスト名を列挙.
あと,$HADOOP_HOME/conf/hosts.include
とりあえず,全部記述.
sv1.example.com
sv2.example.com
sv3.example.com
sv4.example.com
$HADOOP_HOME/conf/hosts.excludeは,touchで空ファイル作っておく.
$ touch hosts.excludeって感じで.
これを作ってなくて,NameNodeが立ち上がらず難儀したw
これで一応設定完了.いよいよ立ち上げ.
まず,NameNode初期化.
hadoop@sv1> ./bin/hadoop namenode -format
で,sv1(NameNode)上で,$HADOOP_HOME/bin/start-all.shを実行.
問題なければ,sv1〜sv4で,それぞれ次のプロセスが立ち上がる.
hadoop@sv1> jps
5478 JobTracker
5025 SecondaryNameNode
4219 NameNode
hadoop@sv2> jps
5933 DataNode
6272 TaskTracker
※sv3,sv4も同様にDataNode,TaskTrackerが立ち上がる.
ま,とりあえずプロセスは起動しましたよ,と.
ちなみにHadoopの停止は,sv1(NameNode)で
$HADOOP_HOME/bin/stop-all.shを実行.
DataNode,TaskTrackerも含め,すべて停止する.
これでとりあえず実行環境まで構築終了.